News
Facebook Open Sources Presto Distributed SQL Query Engine for Big Data
- By David Ramel
- November 7, 2013
Facebook yesterday open sourced Presto, its distributed SQL query engine built to improve Big Data analytics beyond existing solutions such as Hadoop MapReduce and Hive.
The improvements are highlighted by low-latency queries and interactivity, Facebook's Martin Traverso said in a post yesterday. About a year ago, he explained, a team started to tackle the problem of improving analytics on Facebook's 300-petabyte data warehouse, one of the largest in the world. All that information is stored in Hadoop clusters using the Hadoop Distributed File System (HDFS), but existing Big Data query engines didn't provide enough performance.
"Hadoop MapReduce and Hive are designed for large-scale, reliable computation, and are optimized for overall system throughput," Traverso said. "But as our warehouse grew to petabyte scale and our needs evolved, it became clear that we needed an interactive system optimized for low query latency."
Presto has provided up to 10x improvement in CPU efficiency and latency over Hive and MapReduce for most queries, Traverso said. Key to the performance boost are in-memory processing and improved scheduling that eschews the MapReduce system of running tasks consecutively.
The architecture is shown below:
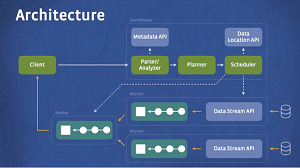 [Click on image for larger view.]
The Presto Architecture (Source: Facebook)
[Click on image for larger view.]
The Presto Architecture (Source: Facebook)
Also, it supports a large part of the ANSI SQL standard and can access several types of disparate data sources. "A single Presto query can combine data from multiple sources, allowing for analytics across your entire organization," claims the Presto site. Those multiple sources include traditional RDBMS systems, Hadoop-related stores such as Apache Hive and Apache HBase, the Facebook-developed Scribe data aggregation server and proprietary systems such as Facebook's News Feed.
Facebook said Presto is used by more than 1,000 employees who each day rack up some 30,000 queries that combined process more than a petabyte of data. It's in use--at least in pilot testing programs--by companies such as Airbnb and Dropbox.
Traverso noted that the biggest restrictions of the system are a limit on the size of joined tables, inability to write data output back to tables and the "cardinality of unique keys/groups." He said the company is working on addressing those restrictions and also improving performance further by developing a new data format optimized to accelerate queries. Another feature in the works is a high-performance HBase connector.
Implemented in Java, Presto is available on GitHub. It runs only on Linux or Mac OS X and requires 64-bit Java 7, Maven 3 and Python 2.4+.
About the Author
David Ramel is an editor and writer at Converge 360.